How to run and create a Reader Test
- Marco Peters
- Sabine Embacher
- Nicolas Ducoin (Unlicensed)
Introduction
The SNAP product reader test is located in the snap-reader tests project.
The tests are defined in the JUnit class org.esa.snap.dataio.ProductReaderAcceptanceTest.
This test class contains 5 different test methods:
testOneIntendedReader - checks if there is only one reader which is intended for a product. Multiple intended readers can cause problems.testPluginDecodeQualifications - checks if returned decode qualification is as expected and the detection of the qualification doesn't take too long.testProductIO_readProduct - simply opens the product, without reading raster data.testProductReadTimes - testing how long reading of data takes and logs the results.
testReadIntendedProductContent - this is the most important test. It ensures that the project structure is as expected, the data is correctly read and the geo-information is as required.
Executing the Reader Tests
Configuration
To run the reader tests, simply execute the JUnit test class ProductReaderAcceptanceTest either in your IDE or with maven.
Java VM system properties are used to configure the execution.
This property enables the acceptance test runner. If not set or set to false, all reader acceptance tests are skipped and a message is printed to the console window. Only unit-level tests are executed in this case.-Dsnap.reader.tests.execute=true
-Dsnap.reader.tests.data.dir=<Path_To_Data>
This property defines the root directory for the test dataset. All test-product definitions are referenced relative to this root directory. If the property is not set or does not denote a valid directory, the test setup fails. The data is at different locations on the server and the local system. But from this specified base folder, the directory structure must be the same.
-Dsnap.reader.tests.failOnMissingData=false
By default, the reader tests fail if test data is missing. This property can be set to false to avoid this. It is helpful for developers if they don't have the complete test data set on their developer machine.
-Dsnap.reader.tests.failOnMultipleIntendedReaders=false
By default, the reader tests fail if there is more then one reader intended for one file. This property can be set to false to avoid this.
-Dsnap.reader.tests.log.file=<Path_To_LogFile>
Specifies the path to the log file which will be written. If not specified, no log file will be created.
-Dsnap.reader.tests.class.name=<ProductReaderPlugIn_ClassName>
If the ProductReaderPlugIn class name is given, the tests for this reader plugin are executed only. It is also possible to indicate the package of the reader plugins: for example, if <ProductReaderPlugIn_ClassName> is "org.esa.s3tbx.dataio.landsat", the tests for all the landsat reader plugins will be executed.
Creating a New Reader Test
In order to define a reader test at least two files must be provided in the resource directory of the reader module. They must be placed in the same package as the implemented reader plugin. The files must follow this naming convention:
<READER_PLUGIN_NAME>-data.json
<PRODUCT-ID>.json
where <PRODUCT-ID> must match the product identifier that is defined within the *-data.json file.
Example for Landsat:
Plugin is
org.esa.snap.dataio.landsat.geotiff.LandsatGeotiffReaderPlugin
The files must be located in
\src\test\resources\org\esa\snap\dataio\landsat\geotiff\LandsatGeotiffReaderPlugin-data.json
\src\test\resources\org\esa\snap\dataio\landsat\geotiff\L71191027_02720070313.json
Within the data file, the test products are defined. Each definition consists of an id, a relative path to the test data and an optional description (see class org.esa.snap.dataio.TestProduct).
{
"testProducts": [
{
"id": "LC81960222013195LGN00",
"relativePath": "sensors_platforms/LANDSAT/LANDSAT_8_OLI_TIRS/geotiff/LC81960222013195LGN00/LC81960222013195LGN00_MTL.txt",
"description": "Landsat 8 OLI_TIRS GeoTIFF Test product, PROCESSING_SOFTWARE_VERSION: LPGS_2.2.2"
},
{
"id": "LT51970222006231KIS02",
"relativePath": "sensors_platforms/LANDSAT/LANDSAT_5_TM/legacy/LT51970222006231KIS02.tar.gz",
"description": "Landsat 5 legacy Test product, PROCESSING_SOFTWARE: LPGS_11.0.0"
},
{
"id": "L71191027_02720070313",
"relativePath": "sensors_platforms/LANDSAT/LANDSAT_7_ETM/legacy/L71191027_02720070313/L71191027_02720070313_MTL.txt",
"description": "Landsat 7 legacy Test product, Product type: Landsat7_ETM+_L1T, PROCESSING_SOFTWARE: LPGS_10.1.0"
}
]
}
Within the product-id file the expected content of the product is defined (see class org.esa.snap.dataio.ExpectedContent).
The file L71191027_02720070313.json shows the example content. How such a file can be created is explained further down, in the section 'Create the Expected Content'.
Defining the Dependencies
There are two different approaches for executing the reader tests:
1. Execute Tests within the Reader Project
In the first case, the dependency to the reader implementation must be added to the dependency list of the snap-reader-tests module. This is the approach used for the toolboxes, like s2tbx and s1tbx.
Attention
Remember to install the reader module to your local maven repository after you have made changes. The dependencies used by the snap-reader-tests link to the installed jars. If not installed the old code will be used for the new test.
After committing the JSON files the reader tests are automatically executed on the build server.
2. Execute Tests within the SNAP Reader Test Project.
For the second approach, the dependency on the snap-reader-test project has to be added to the list of the reader dependencies.
This approach can be used by external reader acceptance tests, like in ProbaVBox or SeaDAS. Here you need to implement a test class extending 'org.esa.snap.dataio.ProductReaderAcceptanceTest', leaving its implementation empty. This is only to have something in the projected which can be started.
In the dependency list of the external module, the usual and the 'test-jar' type of the snap-reader-tests dependency must be added.
<dependency>
<groupId>org.esa.snap</groupId>
<artifactId>snap-reader-tests</artifactId>
<version>${snap.version}</version>
</dependency>
<dependency>
<groupId>org.esa.snap</groupId>
<artifactId>snap-reader-tests</artifactId>
<type>test-jar</type>
<scope>test</scope>
<version>${snap.version}</version>
</dependency>
Create the Expected Content
It is possible to add the snap-reader-tests as a new plugin in SNAP. Once installed, an option in the menu will be available in order to generate the expected content:
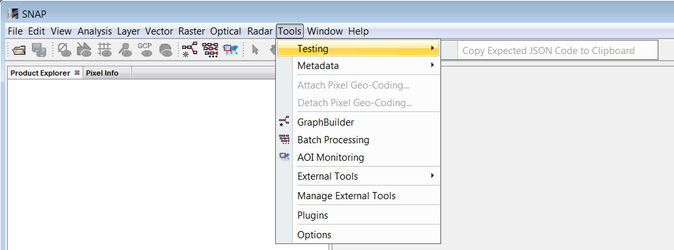
It will generate the expected content by selecting randomly some pixel values for every band, metadata fields... If some pins have been selected in the product, then the pixel values will be collected in these points.
Instead of using the compiled plugin within a SNAP installation, also the cluster which is build can be used within the IDE. The path to the cluster must be set to the '–-cluster' parameter. See also How to run and debug SNAP from an IDE
--clusters "C:\Users\Marco\Projects\senbox\s2tbx\s2tbx-kit\target\netbeans_clusters\s2tbx;C:\Users\Marco\Projects\senbox\snap-reader-tests\target\nbm\netbeans\extra"