Sub-Systems and their Extension Points
- Former user (Deleted)
- Marco Peters
- Nicolas Ducoin (Unlicensed)
- Tonio Fincke
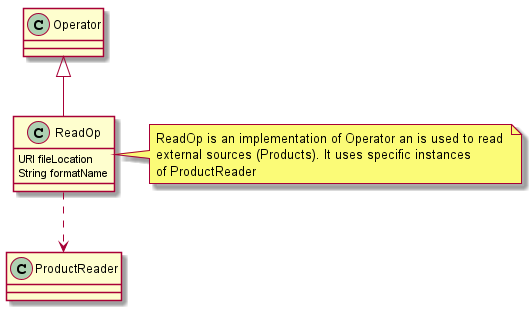
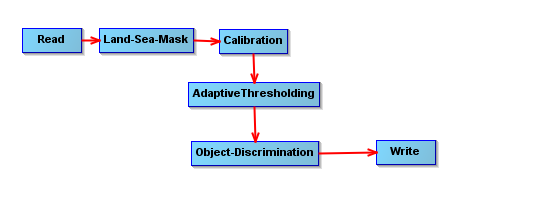
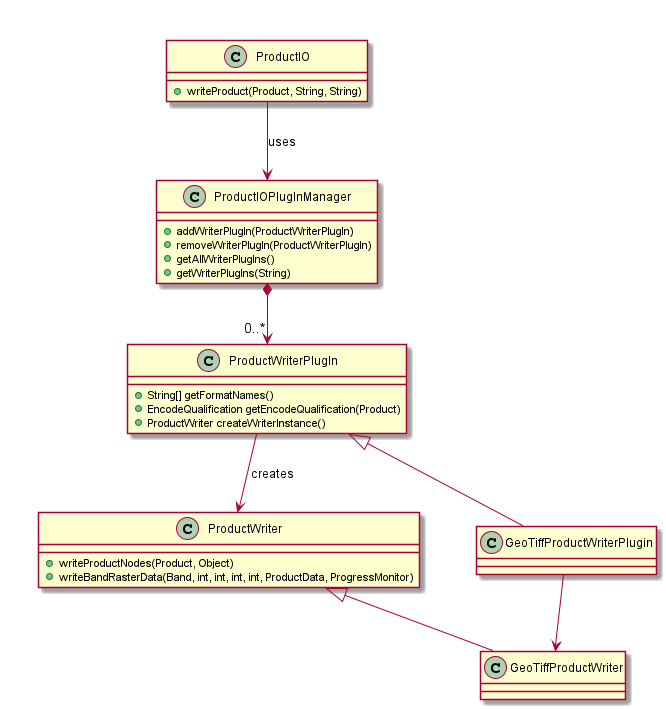
Outdated content The content of this page is not up to date anymore. The general concepts are still valid and the explanation can be helpful for getting started with the SNAP API but several details are not correct anymore. If you have questions please visit the forum and ask your questions. Developers of a new data reader plugin derive a new class from ProductReaderPlugin. An implementation of this interface must provide some reader metadata (format name, file extensions, etc). It also must be able to identify whether a given input object can be decoded by the reader into a Product from its dedicated external data format (canRead method). Once a plugin has been selected (e.g., after the user has selected a corresponding import action from the file menu), a plugin instance is requested to create the ProductReader instance that is actually used to instantiate a Product (readProduct method) for a given input object (e.g. URI). Product readers usually don’t read all data at once. Instead, the platform may request new meta-, vector-, and raster data to be reloaded at any time. API users don’t have to directly deal with the details of the product reader SPI as long as they don’t develop new plugins. The ProductIO class is a high-level façade and is usually sufficient to create new PDM instances given a local or remote file location (method ProductIO.readProduct()). The memory management of the Sentinel Toolbox in general and the PDM specifically are designed in such a manner that very large datasets, usually broadly exceeding the available computer’s RAM, can be handled efficiently by the processing and visualization tools. Only the data currently being requested by the platform (e.g., for visualisation or by a processor) is actually ingested. In some cases the data can be down-sampled to view the desired area at the expense of resolution. As mentioned in Product Data Model, RasterDataNode makes use of tiled images. Raster data is represented and delivered in form of raster tiles. A usual workflow is as follows: The process is then repeated on a new set of tiles. The actual source for raster tile data or vector data is represented by the Operator class. In fact, every PDM instance (usually) has an operator instance which generates the requested data. The Operator class is the abstraction of a data processor: Those operator instances that read from external sources are instances of a ReadOperator, which loads its data from an reader: SNAP uses the Operator concept in its Graph Processing Framework (GPF). The following diagram shows the abstract Operator class in its context of the logic subsystem API. The diagram shows that the SPI concept is also used for processor plugins. It includes the concrete OperatorSpiRegistry as part of the platform and the abstract OperatorSpi and Operator classes to be implemented by a processor plugin developer. API users don’t have to directly deal with the details of the operator SPI as long as they don’t develop new plugins. The GPF class is a high-level façade and is usually sufficient to create new target products from a given operator name, the source products and the processor values (methods GPF.create() in the diagram). Developers don’t need to develop user interfaces for their processor unless there are specific needs. The platform generates a GUI and CLI from the operator metadata provided by the plugin. Operators have an OperatorDescriptor which provides operator metadata such as descriptors of the valid source and target products, and its processing parameters. A ParameterDescriptor includes information about allowed data types, value ranges, value sets, units, etc. of each processor parameter. A ProductDescriptor describes the structure and signature of expected source or resulting target products. This information is used to validate whether operators can be combined in a chain, to provide users visual feedback on applicable processors, and also to automatically generate user interfaces (GUI & CLI) for a given operator. With the OperatorDescriptor information available for each processor, the framework can make a-priori decisions about matching processor chains and raise warnings to the user before starting processing. When using processors from the Sentinel-Toolbox GUI, e.g. the Visual Graph Builder for creating processing chains, users will be presented only processors with a matching signature. In addition, the framework can derive optimisation hints for the processing chain and improve the performance. The following object diagram shows an exemplary processing graph composed of chained products and their associated processors (of type Operator). The example shows four 6 operators, namely the Read, Land-Sea-Mask, Calibration and AdaptiveThresholding, Object-Discremination and Write operations. The writer is the trigger for a data request chain propagated in reverse order through the graph until a request reaches the actual file reader. This concept is referred to as pull-processing and is used throughout the GPF. It is a solution for CPU-intense processing chains because (tile) data requests can be performed in parallel by multiple threads or by GPU support without the need to write intermediate data to disk. It is also a solution for memory-intense processing chains, as data must never be ingested fully into memory. Instead, the chain can usually work on data chunks. The Sentinel Toolbox provides a command-line interface (CLI) which is part of the SNAP graph processing framework. It is used to invoke single operators or processing graphs (loaded from XML files) from the command-line shell. Each processor exports a concise description of its purpose and the parameters to be supplied which assembles up a user help-set that can be requested from the command line. Therefore, users only have to learn a single interface for all operators and predefined processing chains. Sentinel Toolbox operators can be The API for the Product Writing very similar to the API for Product Reading w.r.t. the used SPI concept for plugin development: Developers of a new data writer plugin derive a new class from ProductWriterPlugin. An implementation of this interface must provide some writer metadata (format name, file extensions, etc) and must be able to identify whether a given Product can be encoded by the writer (canWrite method) to its dedicated external data format. Once a plugin has been selected (e.g., by selecting a corresponding export action from the file menu) a plugin instance is requested to create a ProductWriter instance that is used to write the Product (writeProduct method) to an external representation on some storage device. API users don’t have to directly deal with the details of the product writer SPI as long as they don’t develop new plugins. The ProductIO class is usually sufficient API for writing PDM data. Developers of writer plugins may convert the whole Product to an external representation or parts of it. They may also make advantage of the internal image pyramid model, so that tiled GeoTIFF or JPEG2000 image files can be written. A writer may also export plots with associated legends. These results can also be produced from the Sentinel Toolbox command line. If not otherwise specified by the user, the Sentinel Toolbox will write to the user’s home directory. When another directory is given, it is saved as a user preference and used as default directory the next time. The user interface of the Sentinel Toolbox is composed of components that are entirely loaded as dynamic extensions. Given here is a limited number of component types for which extension points are available: The extension points for the component types described above are made available by the NetBeans Rich Client Platform [https://netbeans.org/features/platform/], which is used by the SNAP Desktop application. The NetBeans RCP is actively developed and sponsored by Oracle as it is also the platform for the well-known NetBeans Java IDE. Oracle offers exhaustive documentation and tutorials on NetBeans RCP usage. The NetBeans RCP is used by a number of visual, scientific applications [https://platform.netbeans.org/screenshots.html]. Prominent examples include NASA mission planning software [http://jaxenter.com/developing-nasas-mission-software-with-java-108114.html] and the NATO MASE, an air defence solution [http://netbeans.dzone.com/nb-updated-nato-air-defence-solution]. The SNAP Desktop provides a number of reusable actions, tool windows, and document windows, such as very fast image display components. The SNAP Desktop API provides to GUI developers access to the currently selected PDM Nodes and manipulation and visualisation functions for these.Developing Product Readers
Developing Data Processors (Operators)

Developing Writers
Further Extensions
