GPF Workflows
GPF Workflows
- Former user (Deleted)
- Tonio Fincke
Owned by Former user (Deleted)
Last updated: 2016-11-02 by Tonio Fincke
Goals
- Generalise tile-based pull-processing processing to multi-purpose push-processing workflows, i.e. allow execution of GPF graphs from source(s) to target(s).
- Make pull-processing an implementation detail of GPF operators
- Account for GPF operators that don’t compute tiles (or don’t even output products? maybe later...)
- Allow progress monitoring of whole workflow and individual workflow step execution
Background and strategic fit
A number of GPF operators don't compute target tiles at all: Binning, Mosaicing, Pixel Extraction, Statistics, and many more. In order to trigger their computation, awkward code is usually introduced to trigger the one-time computation of the operator's result. Tile-based pull-processing shall become an implementation detail, a number of operators just implement a new
execute() method.Assumptions
- It is assumed it is always possible to bring processing nodes in a unambiguous order ensuring correct processing of outputs in each step.
- It is assumed that outputs of an operator are still generated by their initialize() methods, otherwise we introduce incompatibility with existing graphs
Requirements
| # | Title | User Story | Importance | Notes |
|---|---|---|---|---|
| 1 | Operator.execute() method | Write operators by implementing a execute() method that takes a progress monitor and a context object as parameter. The context object is used to access the workflow and its steps and can be used e.g. by a target or intermediate step to determine and set appropriate tile sizes to be used by a ReadOp located at the start of the workflow. | Must have | |
| 2 | API to run graphs as workflow |
User interaction and design
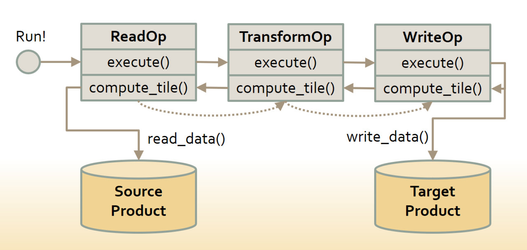
Questions
Below is a list of questions to be addressed as a result of this requirements document:
| Question | Outcome |
|---|---|
| What happens if an operator requires in its "execute"-method the results from another operator's "compute_tile"-method? |
Not Doing
, multiple selections available,
Related content
Cache-less GPF Processing
Cache-less GPF Processing
More like this
Creating a GPF Graph
Creating a GPF Graph
More like this
Support multi-size products in GPF
Support multi-size products in GPF
More like this
Bulk Processing with GPT
Bulk Processing with GPT
More like this
Processing Preview Specification
Processing Preview Specification
More like this
SNAP Project Development
SNAP Project Development
Read with this